Recently one of our customers, Grab - the Uber’s competitor in SEA, unicorn startup - published a blog post on how they moved their data infrastructure from Amazon Redshift to Presto to cater for their scaling needs. We thought it’s pretty interesting and wanted to do a short summary of the post below.
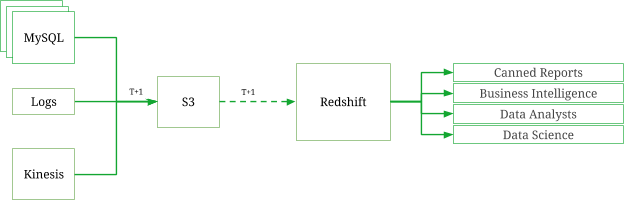
- They were using Amazon Redshift but the data grew really big, and Redshift couldn’t handle
- Built a data lake, separate the storage layer from the data processing layer.
- Storage layer using Amazon S3, data stored as Parquet and compressed for storage optimizations
- Data is collected and aggregated hourly, partitioned and stored in S3 in hourly buckets
- Presto only support ANSI SQL, so they built more UDFs to cater for specific needs
Main reasons of moving from Redshift to Presto:
- They want to move away from monolithic multi-tenant system like Redshift to more generic, multi-cluster architecture, with each cluster catering to specific application of usage.
- Different workloads (data science vs daily reports vs adhoc reports) can be allocated resources differently, so they don’t clash with each other
Recursive Data Processing
One interesting thing they mentioned in the article is the concept of Recursive Data Processing (RDP), where some data when collected hourly, will be changed in the next hour. When a passenger made a booking at hour X and finishes the booking at hour X+1, the booking’s state has changed after the hour X has been processed.
What they had to do is to keep reprocessing the bookings until the final state of the booking data is captured.
Performance Benchmark:
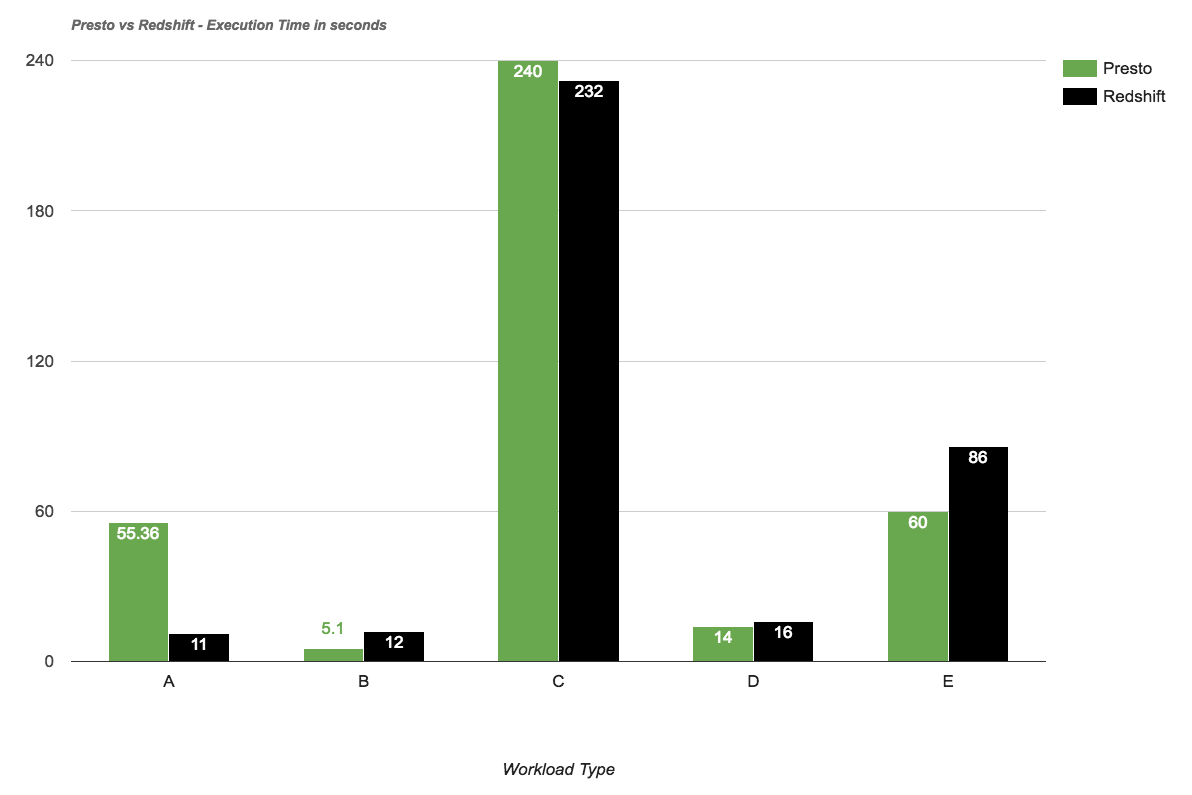
They did some performance benchmark between RS and Presto based on different query types (aggregation, single record fetch, etc):
- Redshift performs far better when it comes to aggregation. This is expected as it’s optimised for this.
- For other cases it’s relatively equal
Writing Optimized Queries in Presto
They also discuss about how to write performant queries in Presto. This part is very good and practical so I quote the entire thing below.
- Always rely on the time-based partition columns whenever querying large datasets. Using the partition columns restricts the amount of data being read from S3 by Presto.
- When joining multiple tables, ordering the join sequences based on the size of the table (from largest to the smallest) provided significant performance benefits and also helped avoid skewness in the data that usually leads to “exceeds memory limit” exceptions on Presto.
- Anything other than equijoin conditions would cause the queries to be extremely slow. We recommend avoiding non equijoin conditions as part of the ON clause, and instead apply them as a filter within the WHERE clause wherever possible.
- Sorting of data using ORDER BY clauses must be avoided, especially when the resulting dataset is large.
- If a query is being filtered to retrieve specific partitions, use of SQL functions on the partitioning columns as part of the filtering condition leads to a really long PLANNING phase, during which Presto is trying to figure out the partitions that need to be read from the source tables. The partition column must be used directly to avoid this effect.
The Results
- Cater for 1.5k - 2k report requests a day
- 400% improve in 90th percentile number (report runtime)
You can read the full article here: http://engineering.grab.com/scaling-like-a-boss-with-presto
Holistics is proud to count Grab as our customer. We provide a powerful BI interface on top of Grab’s scalable data infrastructure (be it Redshift or Presto) - so that Grab’s employees can get their data in timely manner. Learn more about us.